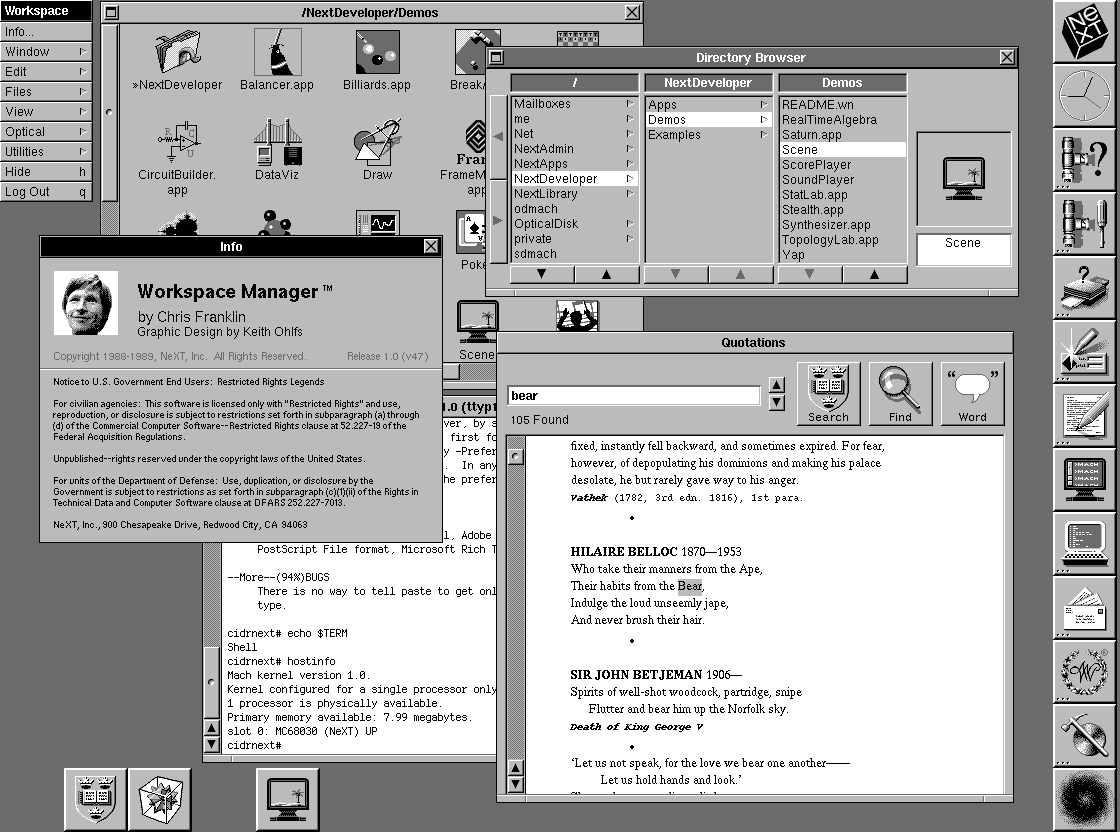
After a brief diversion with the Acme editor (a big part of Plan 9) and some modern Smalltalk environments (Squeak, Cuis, and Pharo), I can't help but feel like we are stuck in a very local optimum as far as UI/UX go.
The insane amount of introspection available to you in a Smalltalk image, and the way every bit of text becomes a potential button or action in Acme just put the lack of creativity in modern interfaces. I say all this as a Haskell and Nix fan as well, so I'm very in-tune to the benefits of functional purity and reproducibility in a computing system. It really makes the silo-ed world of isolated microservices, containers, and walled "garden" ecosystems seem really sad.
I guess this is my way of saying, that we should all try to do things differently. Haskellers, go learn Smalltalk. It's not a big deal that things mutate things when you can literally inspect every object as its running, including the debugger :D. Smalltalkers (or Rubyists or whatever is closest) go learn Haskell. Sometimes boundaries are GOOD. Formality can be very helpful when it comes to organizing, designing, and reasoning about your stuff!
This is how many of the local wireless networks here in Czech Republic started - someone who could have connectivity got together with others, put up an omni-directional antenna on the roof and had others connect to it, then split the cost of the connection. This often made it possible to share much more expensive connections than any one of the participants would otherwise would be able to afford.
This often started with off the shelf wireless APs (like the venerable D-Link DWL-900AP+ with often home made antennas connected. If the network had more knowledgeable Unix people, they might have used an old PC running Linux or BSD with hostapd and an PCI wireless card. The most advanced ones even had home-built optical links (Seriously, 10 Mbit/s full duplex on 2001 by light was super cool! https://en.wikipedia.org/wiki/RONJA) though our network was not that hardcore. :P We did lay some cable via agricultural pipe and build a makeshift com tower next to a Vineyard. :)
Over time the networks got high larger via bridging and wired or even fiber segments and a lot of the hardware was often replaced by high performance Microtik and Ubiquity devices.
Also the networks often merged into bigger ones, covering whole cities and their surrounding villages, with APs on top of grain silos and water towers.
Some of the networks are still independent and quite big, some were bought by big "traditional" telecom companies and some still operate as user coops to this day.
My grandfather was awarded an OBE for his service during WW2, entertaining the troops all over the ME during various stages of battle .. he had some stories of his piano saving him from schrapnel on more than a few occasions, and eventually wrote a book about his experience .. if you're a Kiwi or an Aussie, you can read his book in the National Library:
One thing that always struck me as significant was that his troupe (the "Kiwi Concert Party") was considered a real morale booster and very much respected by every service member it encountered ... I think the idea that a concert could be put on in the most remote places, in the middle of dire battle circumstances, was very inspiring to a lot of the troops.
His adventures always brought to mind the old "Goons" radio show, mixed with a bit of "Dads Army". I was happy to have had piano lessons from the ol' man, anyway ..
And this is why I've been developing all my modern web applications as essentially an S3 bucket of flat HTML with vanilla javascript and jquery sprinkled in sitting behind cloudfront, connected to a fast API built of cloud functions / lambdas written in crystal/rust/etc. I use a custom routing system (I have S3 set up to respond with a 200 at the index in the event of a 404, so I have unlimited control over pathing from within my js logic) and I never let node touch anything at all. And I'm super happy about it. Never has it been easier to get things done. I don't have to fight with any system because there is no system to get in my way.
This gives me:
1. 2-4 second deploys
2. full control over assets pipeline (I call html-minifier, etc., manually in my build script)
3. literally serverless -- S3 or lambda would have to go down for there to be an issue (ignoring db)
4. caching at the edge for everything because of cloudfront
5. zero headaches because I don't have to do battle with node or react or anyone's stupid packages
6. (surprisingly) compatibility with googlebot! It turns out that the googlebot will index js-created content if it is immediate (loaded from a js file that is generated by a lambda and included in the document head tag as an external script, for example)
7. full control over routing, so I don't have to follow some opinionated system's rules and can actually implement the requirements the project manager asks me to implement without making technical excuses.
This does not give me:
1. A magical database that has perfect automatic horizontal scaling. Right now there is no magic bullet for that yet. Some come close but eschew the transactional part of ACID, making themselves basically useless for many applications.
And the parent post exactly matches my usage of jQuery :D
There is one major problem with -- or, rather, cost to -- zero-cost abstractions: they almost always introduce accidental complexity into the programming language originating in the technical inner workings of the compiler and how it generates code (we can say they do a bad job abstracting the compiler), and more than that, they almost always make this accidental complexity viral.
There is a theoretical reason for that. The optimal performance offered by those constructs is almost always a form of specialization, AKA partial evaluation: something that is known statically by the programmer to be true is communicated to the compiler so that it can exploit that knowledge to generate optimal machine code. But that static knowledge percolates through the call stack, especially if the compiler wants to verify — usually through some form of type-checking — that the assertion about that knowledge is, indeed, true. If it is not verified, the compiler can generate incorrect code.
Here is an example from C++ (a contrived one):
Suppose we want to write a subroutine that computes a value based on two arguments:
enum kind { left, right };
int foo(kind k, int x) { return k == left ? do_left(x) : do_right(x); }
And here are some use-sites:
int bar(kind k) { return foo(k, random_int()); }
int baz() { return foo(left, random_int()); }
int qux() { return foo(random_kind(), random_int()); }
The branch on the kind in foo will represent some runtime cost that we deem to be too expensive. To make that “zero cost”, we require the kind to be known statically (and we assume that, indeed, this will be known statically in many callsites). In this contrived example, the compiler will likely inline foo into the caller and eliminate the branch when the caller is baz, and maybe in bar, too, if it is inlined into its caller, but let’s assume the case is more complicated, or we don’t trust the compiler, or that foo is in a shared library, or that foo is a virtual method, so we specialize with a "zero-cost abstraction":
template<kind k> foo(int x) { return k == left ? left(x) : right(x); }
This would immediately require us to change all callsites. In the case of baz we will call foo<left>, in qux we will need to introduce the runtime branch, and in bar, we will need to propagate the zero-cost abstraction up the stack by changing the signature to template<kind k> bar(), which will employ the type system to enforce the zero-cosiness.
You see this pattern appear everywhere with these zero cost abstractions (e.g. async/await, although in that case it’s not strictly necessary; after all, all subroutines are compiled to state machines, as that is essential to the operation of the callstack — otherwise returning to a caller would not be possible, but this requires the compiler to know exactly how the callstack is implemented on a particular platform, and that increases implementation costs).
So a technical decision related to machine-code optimization now becomes part of the code, and in a very intrusive manner, even though the abstraction — the algorithm in foo — has not changed. This is the very definition of accidental complexity. Doing that change at all use sites, all to support a local change, in a large codebase is esepcially painful; it's impossible when foo, or bar, is part of a public API, as it's a breaking change -- all due to some local optimization. Even APIs become infected with accidental complexity, all thanks to zero-cost abstractions!
What is the alternative? JIT compilation! But it has its own tradeoffs... A JIT can perform much more aggressive specialization for several of reasons: 1. it can specialize speculatively and deoptimize if it was wrong; 2. it can specialize across shared-library calls, as shared libraries are compiled only to the intermediate representation, prior to JITting, and 3. it relies on a size-limited dynamic code-cache, which prevents the code-size explosion we'd get if we tried to specialize aggressively AOT; when the code cache fills, it can decide to deoptimize low-priority routines. The speculative optimizations performed by a JIT address the theoretical issue with specialization: a JIT can perform a specialization even if it cannot decisively prove that the information is, indeed, known statically (this is automatic partial evaluation).
A JIT will, therefore, automatically specialize on a per-use-site basis; where possible, it will elide the branch; if not, it will do it. It will even speculate: if at one use site (after inlining) it has so far only encountered `left` it will elide the branch, and will deoptimize if later proven wrong (it may need to introduce a guard, which, in this contrived example will negate the cost of the branch, but in more complex cases it would be a win; also there are ways to introduce cost-free guards -- e.g. by introducing reads from special addresses that will cause segmentation faults if the guard trips, a fault which is caught; OpenJDK's HotSpot does this for some kinds of guards).
For this reason, JITs also solve the trait problem on a per-use-site basis. A callsite that in practice only ever encounters a particular implementation — a monomorphic callsite — would become cost-free (by devirtualization and inlining), and those that don’t — megamorphic callsites — won’t.
So a JIT can give is the same “cost-freedom” without changing the abstraction and introducing accidental complexity. It, therefore, allows for more general abstractions that hide, rather than expose, accidental complexity. JITs have many other benefits, such as allowing runtime debugging/tracing "at full speed" but those are for a separate discussion.
Of course, a JIT comes with its own costs. For one, those automatic optimizations, while more effective than those possible with AOT compilation, are not deterministic — we cannot be sure that the JIT would actually perform them. It adds a warmup time, which can be significant for short-lived programs. It adds RAM overhead by making the runtime more complicated. Finally, it consumes more energy.
There's a similar tradeoff for tracing GC vs. precise monitoring of ownership and lifetime (Rust uses reference-counting GC, which is generally less effective than tracing, in cases where ownership and lifetime are not statically determined), but this comment is already too long.
All of these make JITs less suitable for domains that require absolute control and better determinism (you won't get perfect determinism with Rust on most platforms due to kernel/CPU effects, and not if you rely on its refcounting GC, which is, indeed more deterministic than tracing GC, but not entirely), or are designed to run in RAM- and/or energy-constrained environments — the precise domains that Rust targets. But in all other domains, I think that cost-free abstractions are a pretty big disadvantage compared to a good JIT -- maybe not every cost-free abstraction (some tracking of ownership/lifetime can be helpful even when there is a good tracing GC), but certainly the philosophy of always striving for them. A JIT replaces the zero-cost abstraction philosophy, with a zero-cost use philosophy -- where the use of a very general abstraction can be made cost-free, it (usually) will be (or close to it); when it isn't -- it won't, but the programmer doesn't need to select a different abstraction for some technical, "accidental", reason. That JITs so efficiently compile a much wider variety of languages than AOT compilers can also demonstrate how well they abstract the compiler (or, rather, the languages that employ them do).
So we have two radically different philosohies, both are very well suited for their respective problem domain, and neither is generally superior to the other. Moreover, it's usually easy to tell to which of these domains an application belongs. That's why I like both C++/Rust and Java.
At first, you have the early adopters. Things grow organically and it doesn't feel like a zero-sum game because there aren't many players.
Next comes the growth phase, where more people get involved, and start competing for attention/clicks/votes/whatever points system.
Next comes the exploiters, who discover weaknesses in the system and take advantage of them. They tend to make a lot of money because there's not much competition in this niche.
Next comes the crossover, where the exploit knowledge becomes public, and everyone now must do it because everyone else is.
Next comes the shutout, where the company running things starts actively punishing bad actors, but by this time, being a bad actor is essential to survival, so people do it anyway. It becomes a game of cat-and-mouse, new exploits, new mitigations.
Eventually, the company manages to fix their algorithms enough that the exploits don't offer decent marginal returns anymore, and it returns to what the company originally intended: 1% of people are successful, 99% of people make next to nothing, and the company makes shitloads.
And then the new big thing comes out. The old system goes into decline and the new system starts to take over. Rinse and repeat.
Besides, the appropriate answer is not to censor and hide, but to confront and refute. You want bad ideas to be catalogued and paired with their antidote, not let people remain blissfully unexposed, their mental immune system ready to overreact to the slightest provocation.
That is some of the ideas behind Marc Stiegler's "decision duel" idea in his book "David's Sling" [1]. He envisioned a system where two sides would lay out their arguments, and then the two duelists would link in arguments and counter-arguments to each point. This duel would occur with an audience watching, who would also contribute ideas and research to the duelists.
It is actually the right time to be able to implement something like this now, with the advent of WebGL and other browser technology for the presentation. I was just looking at another HN link about the 'wikigalaxy' visualization system which just hints at what is now possible.
I am to understand that in all of her Majesties kingdoms they have regulations against making things of cardboard such that the front does not fall off.
I did this (non-publicly) many years ago for my eve online alliance. A substantial problem exists in that forging the identity of _someone else_ is fairly easy in a naive scheme if someone detects these characters. That means you can sow chaos by blaming innocent folks. In practice you'll want to "sign" the inserted data as well.
Also because of the overhead here and the fact that you will want the signature to occur at regular intervals a better compression scheme than 0=>char1 1=>char2 is needed. Combining zero width chars and homoglyph substitution* can produce codings which hold signed usernames in only a few characters.
There are other, far more interesting ways, to watermark text than this that are both harder (to impossible) to detect that produce better results.
A few years ago, I was lucky to work with the brilliant Japanese researchers at the Cyber Interface Lab/Hirose-Tanikawa lab (The University of Tokyo).
Amongst their projects (involving AR, VR and multi-modal devices), some students explored various ways to play with our perceptions and define more sharply the interactions and priorities of our senses. Incredible experiments involving simple contraptions as well as more advanced VR, and a lot of scientific creativity (see [1], particularly Multimodal interfaces)
Amongst those projects, Yuki Ban's "Magic Pot" was very similar to what you described, and I remember being almost upset at the realization that the sense we tend to trust the most (vision) can also drive us in the wrong direction the fastest. (see [2] and [3] for more info)
It's not technically a language thing, but I can't get used to the unbelievable verbosity of the method names. (And for calibration purposes: I used to do a lot of Common Lisp.)
In a language inspired by Smalltalk, they turned "at:" into "objectAtIndex:"?
"Hi Alphonse. What's up?" The gruff voice of Bob, Jerry's manager (or "master", as he called him), came from behind them. "Oh, I see Jerry is showing you how to generate unnecessary String garbage and stack overflow exceptions. Wow, and in a simple word wrap function, too. Nice job, Jerry."
Alphonse was confused. "Bob, how do you know that? We didn't write tests for those things. I don't even know if you can write tests for them."
Bob looked at Alphonse with a sad expression. "Jerry, could I see you in my office--sorry, my 'dojo'--for a minute?"
I know this is a curmudgeonly thing to say, but I'm happy to see one of these "implementing Lisp" articles where someone started with a lower-level language than Lisp. It just seems like you miss out on a lot of interesting learning if you start with something like Ruby or Python that is so close to Lisp already.
For example, implementing lambda with a Python lambda...really? You are missing a giant a-ha moment there, as you can see from this article.
Note: implementing a metacircular interpreter for Lisp in Lisp is a beautiful special case exception to my curmudgeonliness.
Hey, someone remembers! (I did the Newton object store.)
I spent years of my life trying to get rid of treating direct user access to the filesystem as a foundational UI metaphor, at both Apple and Microsoft. As I liked to say, why is the UI based on a filesystem debugger? (If you can see /dev or C:\windows\system32, then yeah, you're running a debugger.)
Many people who aren't programmers don't seem to get deep hierarchy (deep meaning > 2 levels). Searching works, tags kind of work, but few people really know how to set up and use a folder hierarchy.
The reason it works to let the app deal with navigation is that the app knows how to do type-specific, contextual navigation. People like concrete things (whereas programmers like abstract things—a constant struggle). If you're trying to find a song, you want to have a UI that knows about songs: they come in albums, the same song may be on multiple albums, they have artists and composers, etc. Any attempt to represent that in a filesystem hierarchy can be nothing but a compromise.
This has nothing to do with defining standard formats for exchanging units of data. Just how you find them once you've stored them.
Speaking as one person who has been interviewing developers (and others) for 20 years, getting to specifics is something I try to do in every interview.
It's just not that difficult to B.S. your way through an interview with great-sounding generalities even when you don't know how to actually do anything (think FizzBuzz). It's also an actual problem in real life that some people would rather live in the abstract and never want get into the details of actually getting work done.
The only way I know to clarify that in an interview is to drill way deep into the specifics of something you've done. If you actually did the work, and knew what you were doing, then that'll be pretty obvious -- and you can certainly motivate the specifics with principles as you go.
However, quite often I have to really push to get the specifics even if they are there. People don't expect that I want to be bored with details, or something. So I've learned to be very explicit that I want boring details, lots of them. It sounds like the interviewers in this case didn't do that, whether deliberately or not.
This takes me back to when computers had a lot fewer layers. He's inspired by Apple ][ and C64, but it's also reminiscent of Smalltalk-80 and Lisp machines, with the live UI links, inspectors, first-class graphic objects... I also enjoyed the birds screeching in mid demo.
{kind=link}
The insane amount of introspection available to you in a Smalltalk image, and the way every bit of text becomes a potential button or action in Acme just put the lack of creativity in modern interfaces. I say all this as a Haskell and Nix fan as well, so I'm very in-tune to the benefits of functional purity and reproducibility in a computing system. It really makes the silo-ed world of isolated microservices, containers, and walled "garden" ecosystems seem really sad.
I guess this is my way of saying, that we should all try to do things differently. Haskellers, go learn Smalltalk. It's not a big deal that things mutate things when you can literally inspect every object as its running, including the debugger :D. Smalltalkers (or Rubyists or whatever is closest) go learn Haskell. Sometimes boundaries are GOOD. Formality can be very helpful when it comes to organizing, designing, and reasoning about your stuff!
And we should all try to do something weird.