The way that semantic search works, they don't cap a relevance score (since it's all relative), and they don't allow you to sort through some kind of time index either.
Generation is usually fast, but prompt processing is the main limitation with local agents. I also have a 128 GB M4 Max. How is the prompt processing on long prompts? processing the system prompt for Goose always takes quite a while for me. I haven't been able to download the 120B yet, but I'm looking to switch to either that or the GLM-4.5-Air for my main driver.
You mentioned "on local agents". I've noticed this too. How do ChatGPT and the others get around this, and provide instant responses on long conversations?
Not getting around it, just benefiting from parallel compute / huge flops of GPUs. Fundamentally, it's just that prefill compute is itself highly parallel and HBM is just that much faster than LPDDR. Effectively H100s and B100s can chew through the prefill in under a second at ~50k token lengths, so the TTFT (Time to First Token) can feel amazingly fast.
Frigate has been an overweight nightmare for me to work with. Trying to detect wildlife that are not in their classification models is basically impossible. I've been better off using motion / motioneye for a lightweight and practical approach
yeah - i've been using it for several years. it's got some issues: fails to detect cars and trucks at night (apparently it doesn't know what to do with the moving headlights); also frequently fails to detect me walking past the camera with my 4 small dogs on our morning walk; confuses farm equipment for cars and continues to record even when the object is stationary. still it's better than most of the other software i've tried.
Nah, these are much smaller models than Qwen3 and GLM 4.5 with similar performance. Fewer parameters and fewer bits per parameter. They are much more impressive and will run on garden variety gaming PCs at more than usable speed. I can't wait to try on my 4090 at home.
There's basically no reason to run other open source models now that these are available, at least for non-multimodal tasks.
Qwen3 has multiple variants ranging from larger (230B) than these models to significantly smaller (0.6b), with a huge number of options in between. For each of those models they also release quantized versions (your "fewer bits per parameter).
I'm still withholding judgement until I see benchmarks, but every point you tried to make regarding model size and parameter size is wrong. Qwen has more variety on every level, and performs extremely well. That's before getting into the MoE variants of the models.
The benchmarks of the OpenAI models are comparable to the largest variants of other open models. The smaller variants of other open models are much worse.
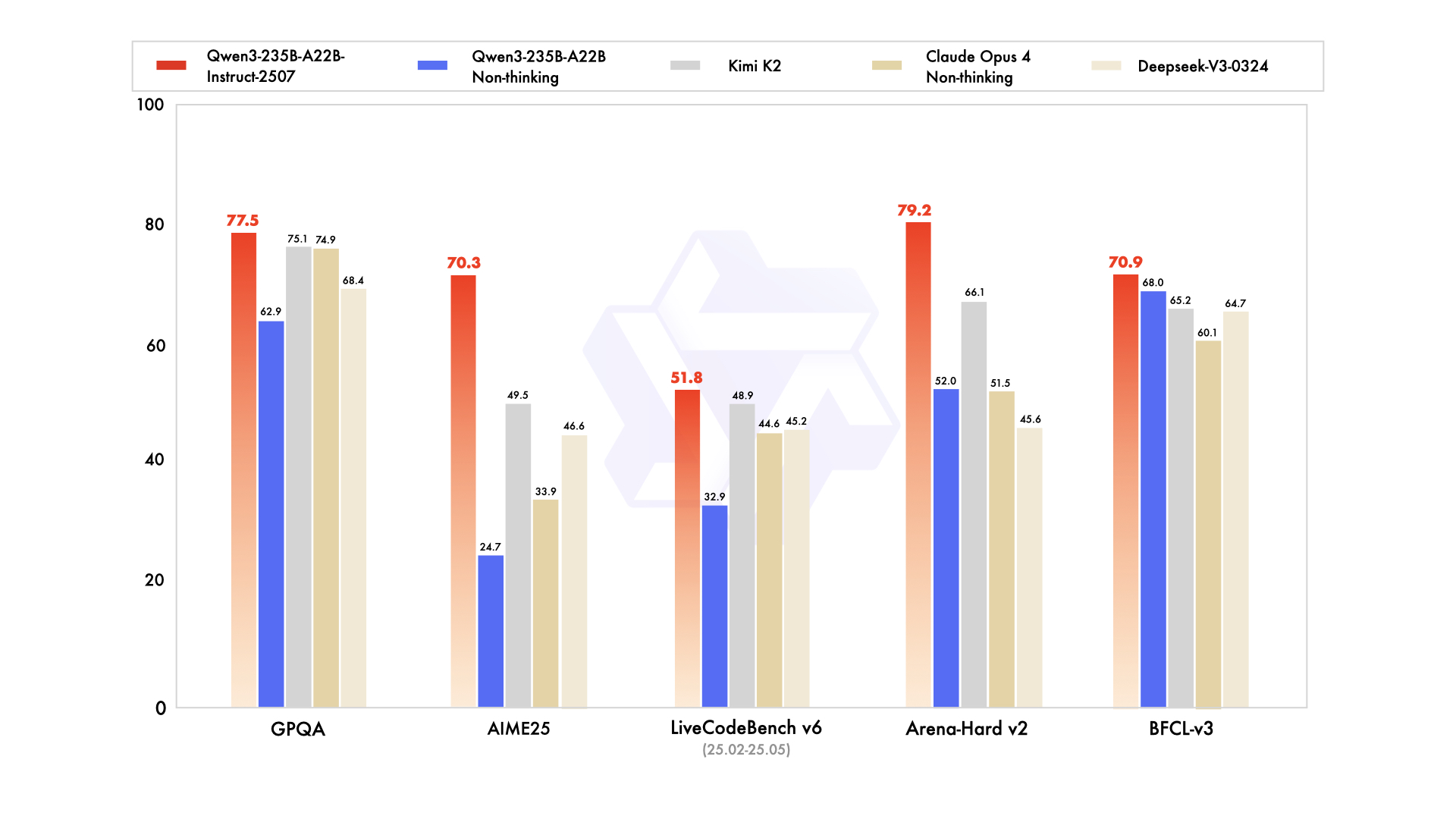
With all due respect, you need to actually test out Qwen3 2507 or GLM 4.5 before making these sorts of claims. Both of them are comparable to OpenAI's largest models and even bench favorably to Deepseek and Opus: https://cdn-uploads.huggingface.co/production/uploads/62430a...
It's cool to see OpenAI throw their hat in the ring, but you're smoking straight hopium if you think there's "no reason to run other open source models now" in earnest. If OpenAI never released these models, the state-of-the-art would not look significantly different for local LLMs. This is almost a nothingburger if not for the simple novelty of OpenAI releasing an Open AI for once in their life.
I'd really wait for additional neutral benchmarks, I asked the 20b model on low reasoning effort which number is larger 9.9 or 9.11 and it got it wrong.
They have worse scores than recent open source releases on a number of agentic and coding benchmarks, so if absolute quality is what you're after and not just cost/efficiency, you'd probably still be running those models.
Let's not forget, this is a thinking model that has a significantly worse scores on Aider-Polyglot than the non-thinking Qwen3-235B-A22B-Instruct-2507, a worse TAUBench score than the smaller GLM-4.5 Air, and a worse SWE-Bench verified score than the (3x the size) GLM-4.5. So the results, at least in terms of benchmarks, are not really clear-cut.
From a vibes perspective, the non-reasoners Kimi-K2-Instruct and the aforementioned non-thinking Qwen3 235B are much better at frontend design. (Tested privately, but fully expecting DesignArena to back me up in the following weeks.)
OpenAI has delivered something astonishing for the size, for sure. But your claim is just an exaggeration. And OpenAI have, unsurprisingly, highlighted only the benchmarks where they do _really_ well.
So far I have mixed impressions, but they do indeed seem noticeably weaker than comparably-sized Qwen3 / GLM4.5 models. Part of the reason may be that the oai models do appear to be much more lobotomized than their Chinese counterparts (which are surprisingly uncensored). There's research showing that "aligning" a model makes it dumber.
The censorship here in China is only about public discussions / spaces. You cannot like have a website telling you about the crimes of the party. But downloading some compressed matrix re-spouting the said crimes, nobody gives a damn.
We seem to censor organized large scale complaints and viral mind virii, but we never quite forbid people at home to read some generated knowledge from an obscure hard to use software.
Writing to catalogs is still pretty new. Databricks has recently been pushing delta-kernel-rs that DuckDb has a connector set up for, and there’s support for writing via Python with the Polars package through delta-rs. For small-time developers this has been pretty helpful for me and influential in picking delta lake over iceberg.
The dependency on a catalog in Iceberg made it more complicated for simple cases than Delta, where a directory hierarchy was sufficient - if I was understanding the PyIceberg docs correctly.
I'll answer in his place, he said he's using ArgoCD and running everything on k3s.
ArgoCD watches the files in a repo (kubernetes yaml manifests for example) and applies them in the cluster, so that the state of the running cluster (applications) is synchronized with the git repo.
{kind=link}