Strictly speaking, I don't think it is the generation or creation that diminishes their value. it is the consumption.
You said it too:
> If I see a million fake Tom Cruise videos, then it oversaturates my desire for desire for all Tom Cruise movies.
The trick of course is to keep yourself from seeing that content.
The other nuance is that as long as real performance remains unique, which so far it is, we can appreciate more what flesh and blood brings to the table. For example, I can appreciate the reality of the people in a picture or a video that is captured by a regular camera; it's AI version lacks that spunk (for now).
Note that iPhone in its default settings is already altering the reality, so AI generation is far right on that slippery axis.
Perhaps, AI and VR would be the reason why our real hangouts would be more appreciated even if they become rare events in the future.
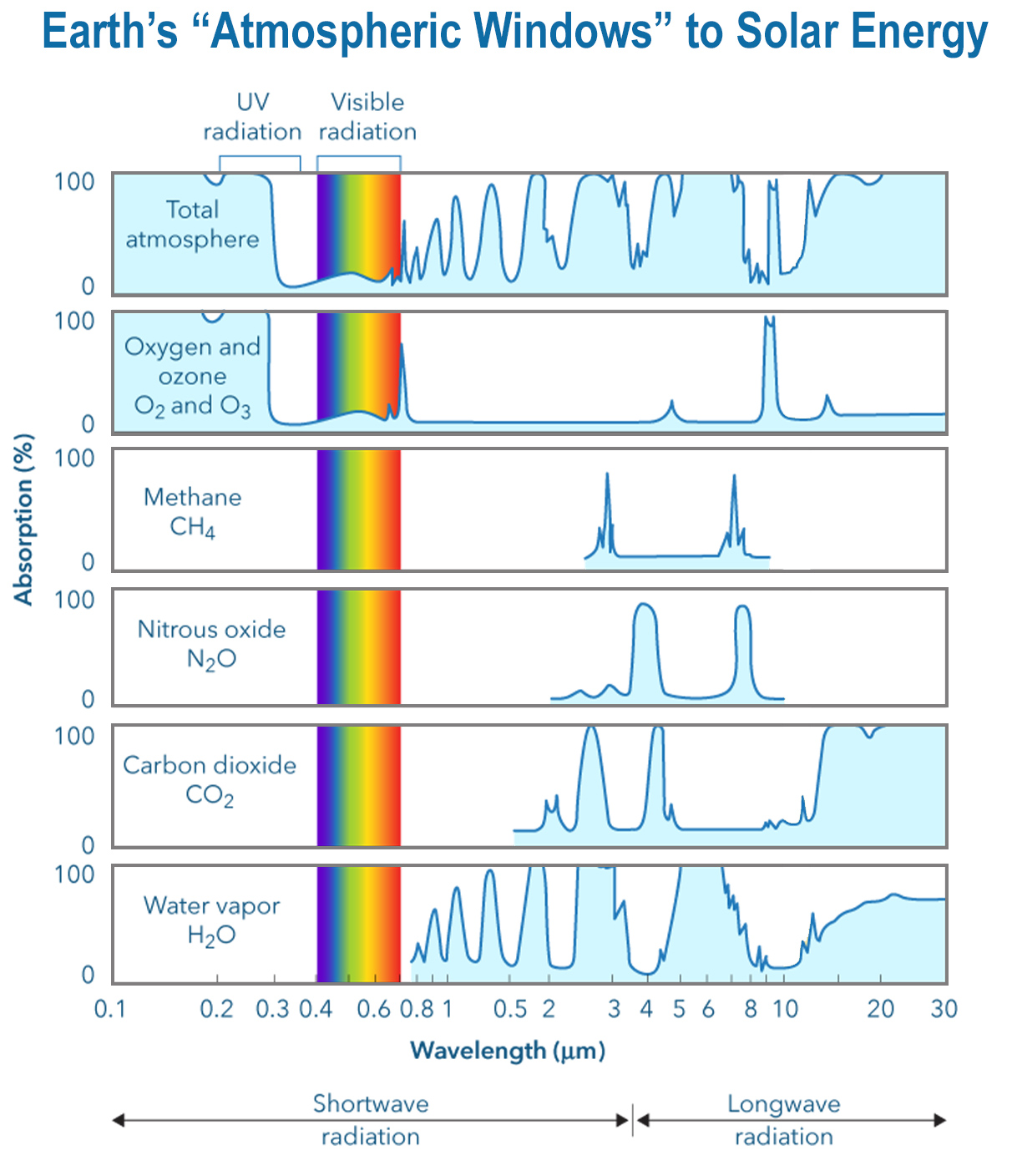
I think we can simplify the answer to this question for most audience and say "the air is blue".
If they say, the air appears to be clear when I stare at something other than sky, the answer is you need more of air to be able to see its blue-ness, in much the same way that a small amount of murky water in your palm appears clear, but a lot of it does not.
If they ask, why don't I see that blue-ness at dawn or dusk, the answer is that the light source is at a different angle. The color of most objects changes when the light source is at a flat angle. And sun lights hits at a flat angle at dawn and dusk.
If they ask, what exactly is the inside phenomenon to see the sky color to be blue, then explanations like this blog are relevant.
If they ask, what exactly is a color, the answer is that it is a fiction made up by our brain.
As confusion elsewhere on this page illustrates, one also needs to clarify absorption. "It's just blue" sky and "it's just blue" stained-glass have quite different behavior. Both side scatter some blue, but while one mostly transmits the rest, the other mostly absorbs the rest, for very different experiences peering through it.
Yes, to all the the scattering, the sky has, you have water and other material relevant for absorption in the path. In the end even the colour of the ground might matter. In the past some people said, that the sea is blue, because it's a reflection of the blue sky, but that covers only a part of the problem.
Yes, I came here to say this. The whole topic drives me crazy. Air is just blue. Everything is a color because of some physics reason. Some birds have blue wings due to microscopic structures and how light interacts with them, rather than pigment.
If you took a large column of air into space and shined white light through it, it would be blue.
No, it would look red. The weird thing about air is that it's not reflection or absorption that gives the color, but scattering, and that means the color is strongly dependent on what direction you are looking at it from in a way that most transparent mediums aren't.
Ok, so the air would be red from one angle, blue from another. In each case, that is what color the air “really” is, in the same sense that a butterfly’s wings are blue (but not from every angle)
Except that one is transmissive and the other reflective. They're not the same kind of thing. TBH I feel like a demo like this is the only way to get an intuitive feel for it: https://www.youtube.com/watch?v=-Xx7sPPTu3Y .
(I agree that just going on about Rayleigh scattering is probably overly obtuse: at least not without explaining that scattering is part of how color is formed in the first place. But it's also not just a case of 'well air is blue like apple juice is orange')
The other is knowing what the collaboration brings to the table and shaping the rules of engagement to fit that expectation. Sometimes you collaborate with SMEs; they bring the domain knowledge - you don't, but you understand the goal better than them. Sometimes you are creating or refining the corporate strategy based on the actions from individual projects or partners; you are learning ground realities from them. Sometimes you need help from others to improve your take on a subject.
In each of these cases, you have to be clear about what you expect from the collaborators (and motivate them to contribute). Without being clear on what the collaboration is about and what they get in return is the number one killer of collaborative projects even though there is no ill-intent anywhere.
It boils down to whether your LLMs can speak graph queries better than SQL, for your use cases and data. As your data posture changes and your use cases change, you routinely reevaluate which DB query language suits best for LLMs.
I'd also design the system architecture in such a way that your non-agentic workloads don't suffer if you have to move between query models for serving agentic workloads better.
It feels to me that the hypothesis of this research was somewhat "begging the question". Reasoning models are trained to spit some tokens out that increase the chance of the models spitting the right answer at the end. That is, the training process is singularly optimizing for the right answer, not the reasoning tokens.
Why would you then assume the reasoning tokens will include hints supplied in the prompt "faithfully"? The model may or may not include the hints - depending on whether the model activations believe those hints are necessary to arrive at the answer. In their experiments, they found between 20% and 40% of the time, the models included those hints. Naively, that sounds unsurprising to me.
Even in the second experiment when they trained the model to use hints, the optimization was around the answer, not the tokens. I am not surprised the models did not include the hints because they are not trained to include the hints.
That said, and in spite of me potentially coming across as an unsurprised-by-the-result reader, it is a good experiment because "now we have some experimental results" to lean into.
Kudos to Anthropic for continuing to study these models.
tadkar did a good job at explaining ColBERT. I understood ColBERT well in the context of where it lies on the spectrum of choices.
On one side of the spectrum, you reduce each of the documents as well as the query to a lower-dimensional space (aka embeddings) and perform similarity. This has the advantage that the document embeddings could be precomputed. At query time, you only compute the query embedding and compare its similarity with document embeddings. The problem is that the lower-dimensional embedding acts as a decent, but not great, proxy for the documents as well as for the query. Your query-document similarity is only as good as the semantics that could be captured in those lower-dimensional embeddings.
On the other side of the spectrum, you consider the query with each document (as a pair) and see how much the query "attends" to each of the documents. The power of trained attention weights means that you get a much reliable similarity score. The problem is that this approach requires you to run attention-forward-pass as many times as there are documents -- for each query. In other words, this has a performance issue.
ColBERT sits in the middle of the spectrum. It "attends" to each of the documents separately and captures the lower-dimensional embedding for each token in each document. This we precompute. Once we have done that, we captured the essence of how tokens within a given document attend to each other, and is captured in the token embeddings.
Then, at query time, we do the same for each token in the query. And we see which query-token embedding is greatly similar to which document-token embedding. If we find that there is a document which has more tokens that are found to be greatly similar to the query tokens, then we consider that to the best document match. (The degree of similarity between each query-document token is used to score the ranking - it is called Sum of MaxSim).
Obviously, attention based similarity, like in the second approach, is better than reducing to token embeddings and scoring similarity. But ColBERT avoids the performance hit compared to the second approach. ColBERT also avoids the lower fidelity of "reducing the entire document to a lower-dimensional space issue" because it reduces each token in the document separately.
By the way, the first approach is what bi-encoders do. The second approach is cross-encoding.
When thinking about AI agents, there is still conflation between how to decide the next step to take vs what information is needed to decide the next step.
If runtime information is insufficient, we can use AI/ML models to fill that information. But deciding the next step could be done ahead of time assuming complete information.
Most AI agent examples short circuit these two steps. When faced with unstructured or insufficient information, the program asks the LLM/AI model to decide the next step. Instead, we could ask the LLM/AI model to structure/predict necessary information and use pre-defined rules to drive the process.
This approach will translate most [1] "Agent" examples into "Workflow" examples. The quotes here are meant to imply Anthropic's definition of these terms.
[1] I said "most" because there might be continuous world systems (such as real world simulacrum) that will require a very large number of rules and is probably impractical to define each of them. I believe those systems are an exception, not a rule.
> Beyond this, if you want to determine causality, e.g. whether events are "causally related" (happened before or after each other) or are "concurrent" (entirely independent of), you can look at Vector Clocks—I won't go down that rabbit-hole here, though.
Perhaps these findings might be indicating that we need more NN layers/attention blocks for performing reasoning. This project circumvented the lack of more trained layers by looping the input through currently trained layers more than once.
Also we may have to look for better loss functions than ones that help us predict the next token to train the models if the objective is reasoning.
{kind=link}
You said it too:
> If I see a million fake Tom Cruise videos, then it oversaturates my desire for desire for all Tom Cruise movies.
The trick of course is to keep yourself from seeing that content.
The other nuance is that as long as real performance remains unique, which so far it is, we can appreciate more what flesh and blood brings to the table. For example, I can appreciate the reality of the people in a picture or a video that is captured by a regular camera; it's AI version lacks that spunk (for now).
Note that iPhone in its default settings is already altering the reality, so AI generation is far right on that slippery axis.
Perhaps, AI and VR would be the reason why our real hangouts would be more appreciated even if they become rare events in the future.